Your LLM Bill Is Too High. Here's How to Fix It (Part 3)
LLM Engineering

Batch, Flex, Priority, and Long Context: The Pricing Modes Nobody Reads
The same model can be cheap or expensive depending on how you call it.
Previously in the series
Part 1 argued that the cheapest LLM call is the one you never make. Part 2 showed why model selection should be a routing menu, not a popularity contest: cheap models should handle narrow, high-volume work while frontier models stay on the exception path. But even after you pick the right model, you can still overpay badly if you call it through the wrong pricing lane. That is where Batch, Flex, Priority, and long-context pricing start to matter.
Before rewriting your whole LLM app, check your pricing mode. Many teams run latency-tolerant jobs through standard interactive APIs, then wonder why costs are high. That is leaving money on the table.
Pricing is not just model selection. It is also processing tier, latency tolerance, context size, and whether the work needs to happen right now.
The pricing modes that matter
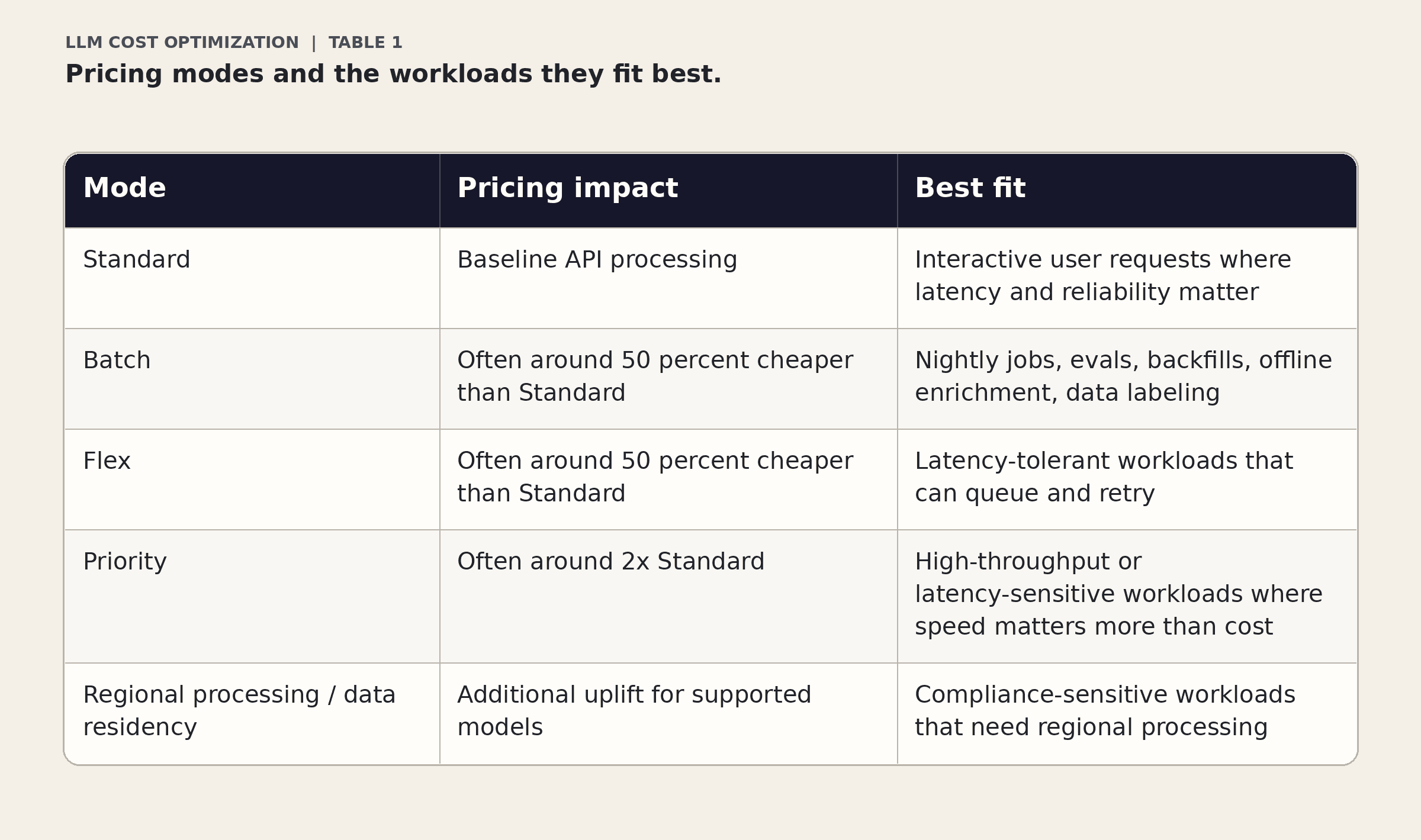

Figure 1. Your processing tier can change cost before you change a single prompt.
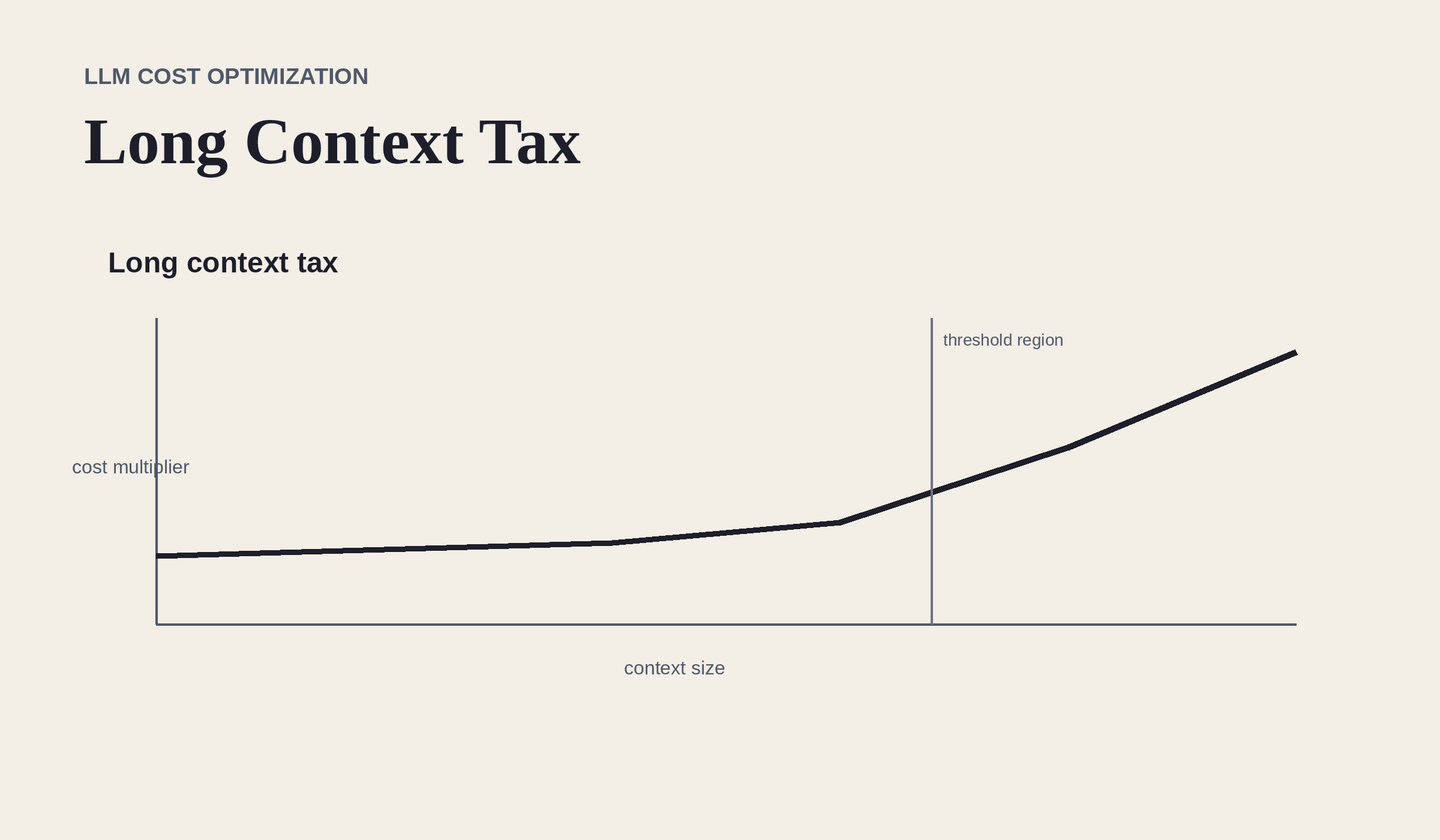
Figure 2. Long context can move a request into a higher-cost zone even when the model name stays the same.
Example: Standard versus Batch or Flex
In the original pricing example, GPT-5.4 Standard pricing is $2.50 per 1M input tokens, $0.25 per 1M cached input tokens, and $15 per 1M output tokens. Batch and Flex cut that roughly in half, to $1.25 input, about $0.13 cached input, and $7.50 output.
That means the same workload can be dramatically cheaper if it does not need interactive latency.
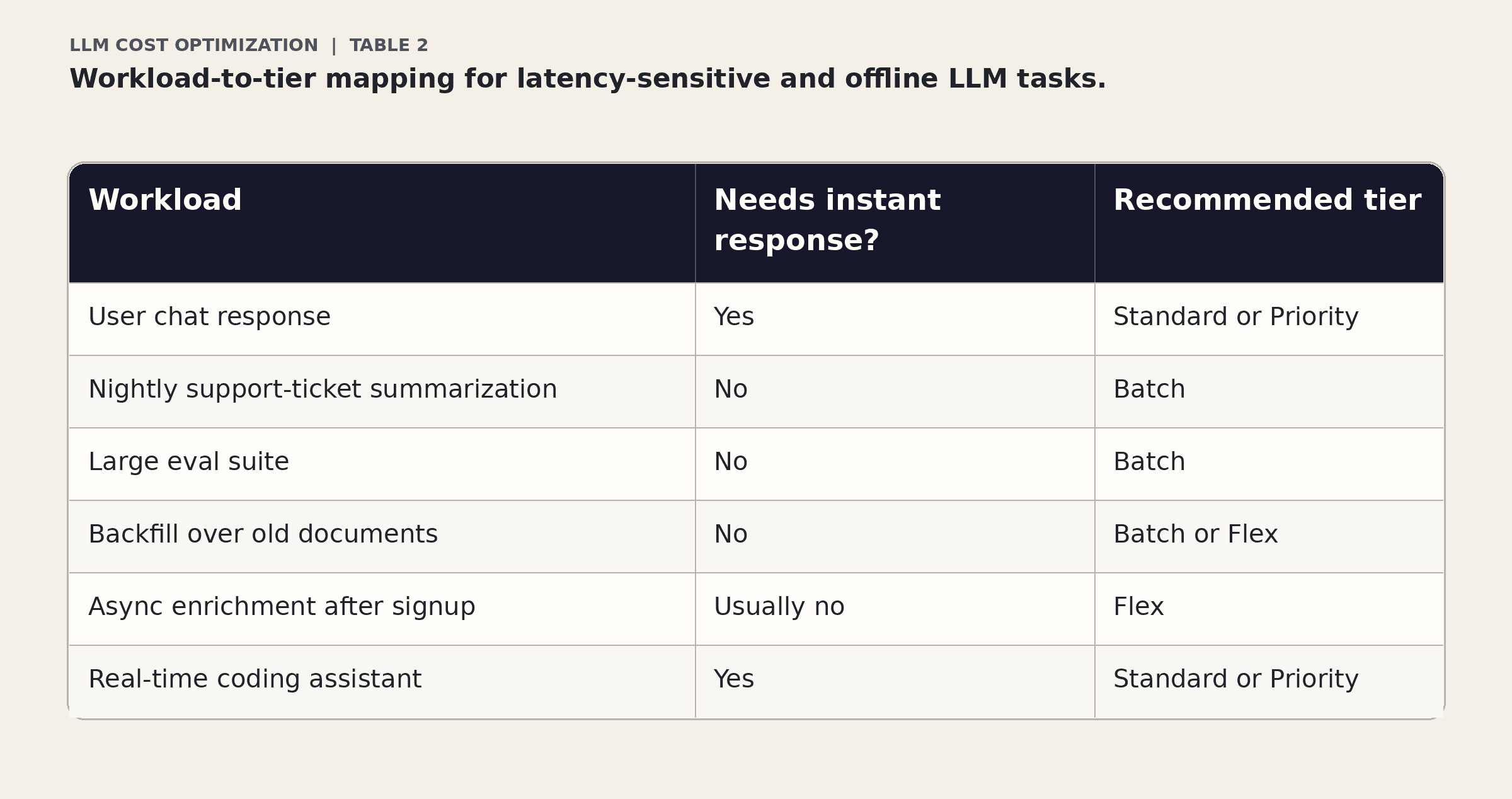
Classify your workload before choosing a tier
Long context is not free
Long context windows are useful, but they are not an excuse to dump everything into every prompt. In the original article, sessions above the long-context threshold are described as premium long-context inference. Treat giant prompts like expensive infrastructure because that is exactly what they are.
Rule: just because a model can accept a huge context does not mean your app should send one.
Practical checklist
Is this request interactive or offline?
Can this run later through Batch?
Can it tolerate queuing through Flex?
Are you paying Priority for work that does not need it?
Are huge prompts crossing premium long-context thresholds?
Can retrieval narrow the context before inference?
Bottom line
Pricing modes are boring, which is exactly why they matter. You can cut costs before touching model quality, app logic, or user experience. Put latency-tolerant work on latency-tolerant pricing.
Next in the series
Part 4 is about the hidden tax inside reasoning models. A response can look short while the model burns thousands of reasoning tokens behind the scenes. We will look at when reasoning is worth paying for, when it is pure waste, and how to cap it before it quietly becomes your biggest cost driver.