Your LLM Bill Is Too High. Here's How to Fix It (Part 2)
LLM Engineering

The best model is the cheapest model that clears your eval for this exact task.
Teams love asking, “What is the best LLM?” That is the wrong question. Frontier models are trained to do almost everything, which means you pay for all of that capability even when you only need to extract a date, classify a support ticket, rewrite a short email, or summarize a page.
The right question is narrower and more useful: what is the cheapest model that passes your eval for this exact step?
Why leaderboards mislead production teams
Benchmarks are useful, but they are not your workload. A model that is excellent at graduate-level reasoning may be overkill for routing inbound tickets. A model that is weaker overall may be perfectly adequate for high-volume extraction. Paying for general intelligence when the step only needs a narrow behavior is how AI bills get bloated.
Rule: do not pick one model for the whole app. Pick the cheapest acceptable model for each step in the workflow.
Current model tiers worth testing
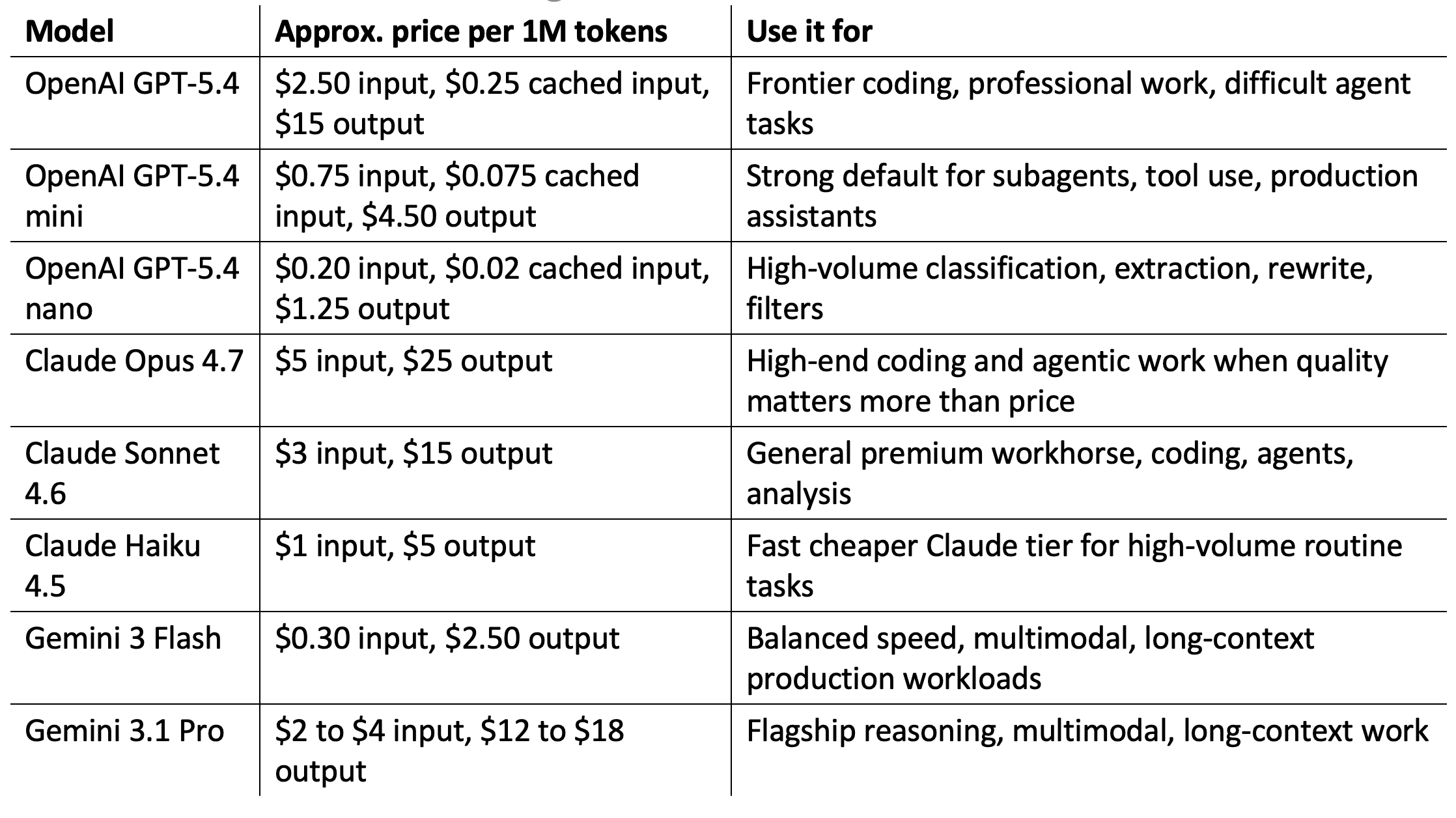
Table 1. LLM Model Pricing & Use Case Reference

Figure 1. Treat model options as a routing menu, not a single winner-take-all leaderboard.
Build an eval matrix, not a vibe check
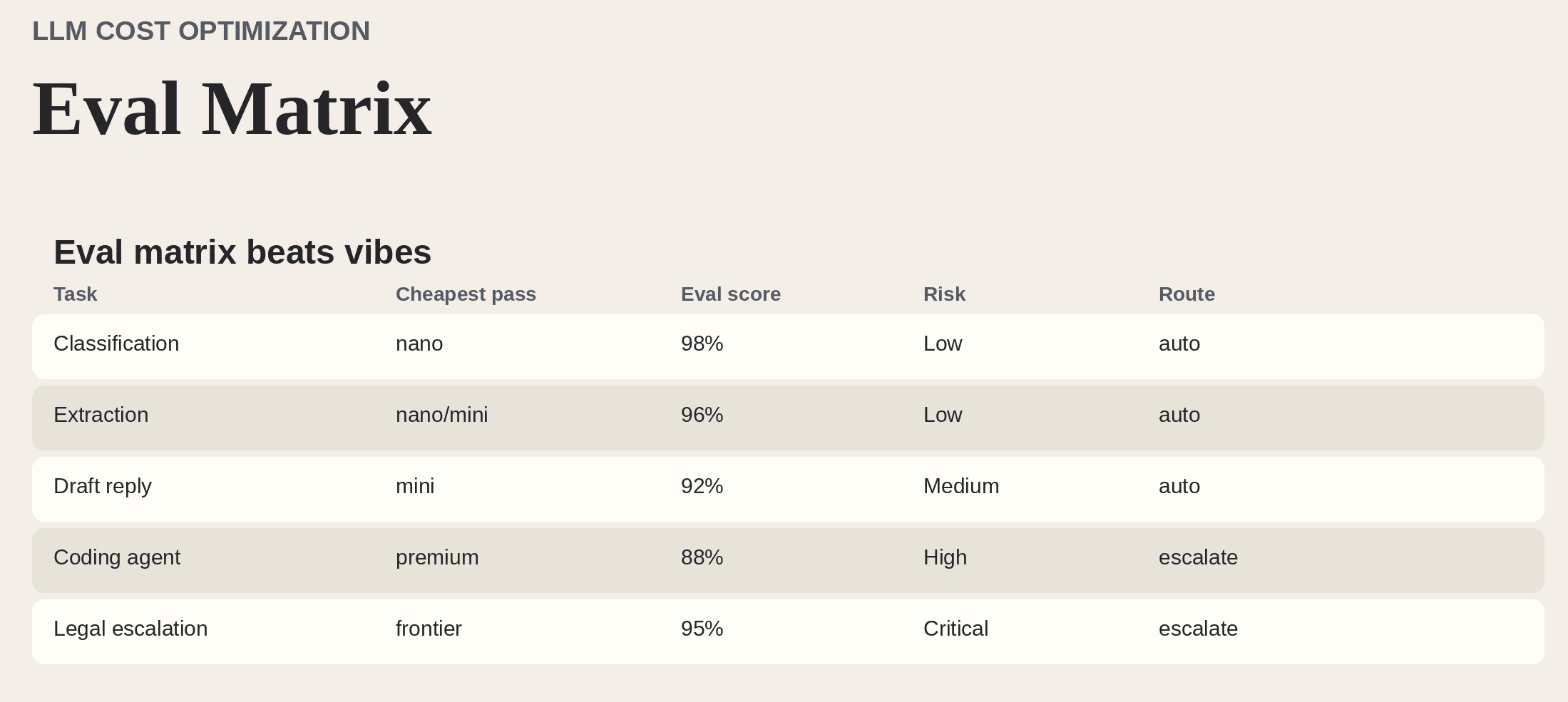
Figure 2. A simple eval matrix turns model selection into an engineering decision instead of a leaderboard debate.
How to test properly
1. Collect real examples from production or realistic test data.
2. Define pass/fail criteria for each step.
3. Test cheap models first, then move upward only when needed.
4. Measure workflow success, not isolated model elegance.
5. Track retries and escalations, because failed cheap calls are not cheap.
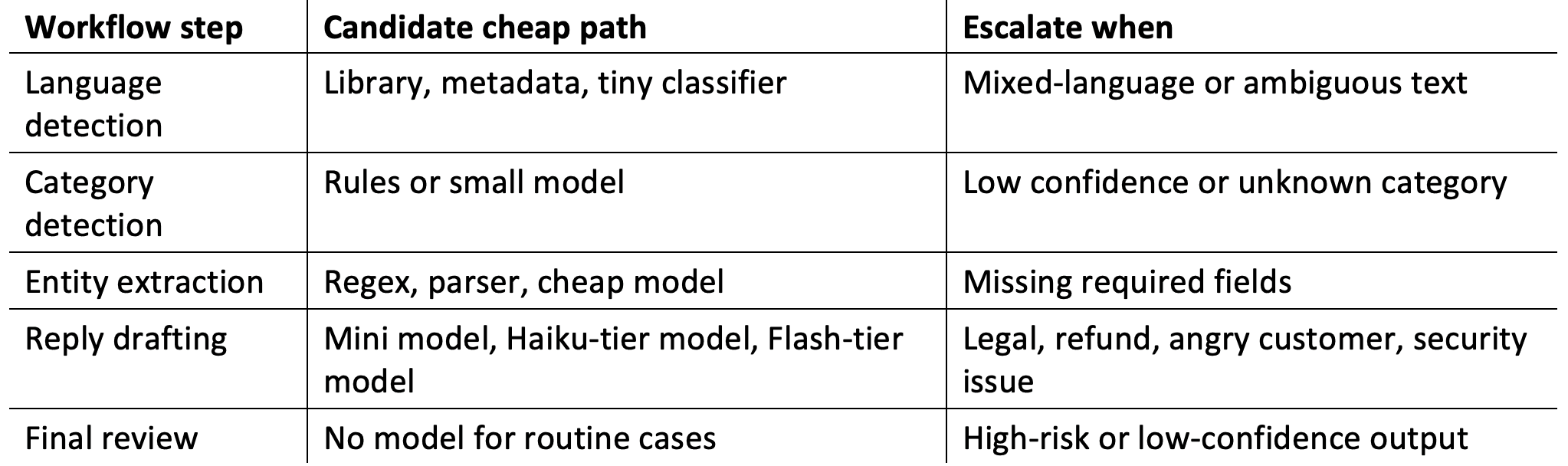
Table 2. AI Agent Workflow: Cheap Path vs. Escalation Triggers
Bottom line
The best LLM is not the strongest one. It is the cheapest one that reliably completes the job. Model selection is not a brand decision. It is a routing and evaluation discipline.