Your LLM Bill Is Too High. Here's How to Fix It (Part 1)
LLM Engineering

This series is for anyone building with LLMs who has already learned the uncomfortable truth: the demo is easy, but the bill is where reality shows up.
Across the next 6 posts, I’ll break down the cost levers that actually matter in production systems, from knowing when not to call a model at all, to choosing the cheapest model that passes your evals, using pricing modes like Batch and Flex, controlling reasoning tokens, designing smarter routing, measuring cost per successful task, and making prompt caching work for real agent workflows.
The goal is not to make AI slightly cheaper. The goal is to show how serious teams redesign the cost structure of LLM applications so expensive frontier models become the exception path, not the default path. If you are building agents, AI products, internal tools, or anything that touches LLM APIs at scale, this series will give you the practical playbook I wish more teams had before their first painful invoice.
Stop Calling an LLM for Everything
The cheapest LLM call is the one you do not make.
Everyone building with LLMs eventually hits the same wall. The prototype works, usage climbs, and suddenly the API bill starts doing things nobody planned for. The problem is usually not that AI is expensive. The problem is that teams are using models for work that should never have touched a model in the first place.
Before you debate GPT versus Claude versus Gemini, ask a more basic question: Do you need an LLM at all?
Rule: use an LLM when the task requires ambiguity handling, judgment, synthesis, flexible natural-language generation, complex reasoning, or tool use. Do not use one because the word AI looks good in the architecture diagram.
The no-model audit
Task | Start here before an LLM | Use an LLM when |
|---|---|---|
Meeting transcription | Dedicated speech-to-text service | You need synthesis, follow-up extraction, or action-item judgment. |
Translation | Translation API or cheaper model | The task needs tone adaptation, context-aware rewriting, or multilingual reasoning. |
Structured document extraction | OCR, document parser, AWS Textract-style pipeline | The document layout is messy, fields are ambiguous, or human-like interpretation is required. |
Small taxonomy classification | Keyword rules, regex, small classifier | Categories overlap, labels are subjective, or confidence is low. |
Formatting and validation | Schema validation, deterministic code | The output needs natural-language repair or explanation. |
Table 1. When to Reach for an LLM (and When Not To)
A shocking amount of production LLM spend is expensive glue around work that deterministic code, dedicated APIs, or cheaper ML services already handle well.
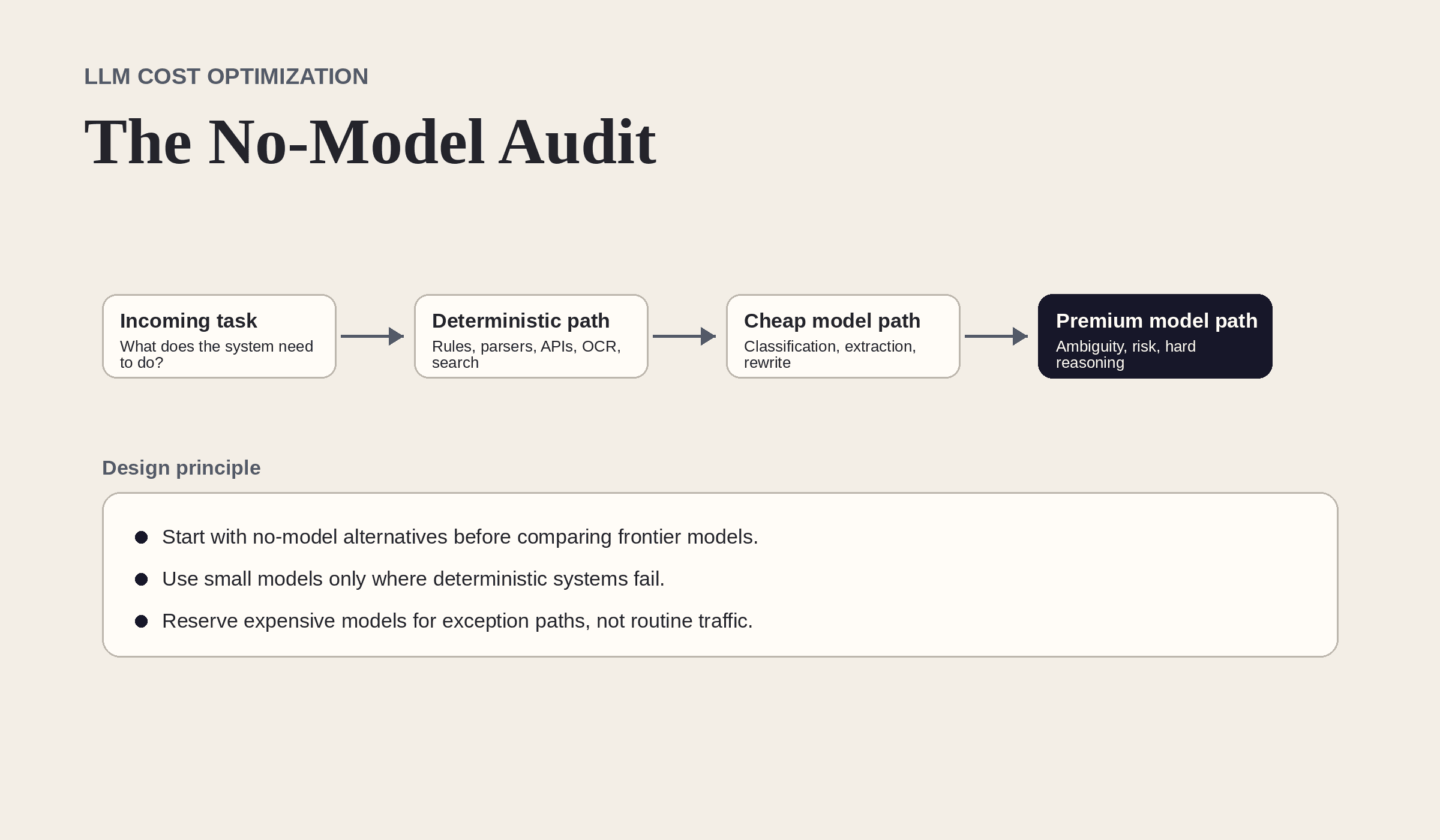
Figure 1. A no-model-first audit prevents teams from paying frontier-model prices for deterministic work.
Where teams waste money

Figure 2. Illustrative savings potential by optimization lever. Actual savings vary by workload and traffic shape.
The common pattern is simple. A team builds a general-purpose prompt, points every request at a strong model, and ships. It works, so nobody questions the architecture until the bill arrives. By then, the model has become the default path for classification, extraction, routing, formatting, translation, rewriting, and exception handling.
That is backwards. The model should not be the default path. The model should be the judgment path.
A better default architecture
Validate inputs with code. Reject malformed payloads before spending tokens.
Use deterministic tools first. Regex, parsers, lookup tables, and APIs are boring. That is why they are cheap and reliable.
Use small models for fuzzy but routine tasks. Classification, extraction, and rewriting usually do not need a frontier model.
Escalate only when confidence is low. Premium models should handle ambiguity, high-risk cases, and hard reasoning.
Practical checklist
Can the task be solved with deterministic code?
Can a dedicated API solve it more cheaply and consistently?
Can a small classifier handle the common path?
Are you sending repetitive context that could be cached?
Is the frontier model reserved for exception cases?
Bottom line
The first cost optimization step is not prompt compression. It is architectural honesty. Most requests are boring. Treat them that way, and the bill starts dropping before you even switch models.